Harnessing the Power of DataOps: A New Era of Data Workflow Efficiency
- Benjamin Tabares Jr

- Mar 6, 2025
- 4 min read
Updated: Mar 26, 2025

Recently, I’ve been exploring Fundamentals of Data Engineering by Joe Reis and Matt Housley, which provides valuable insights into building robust data architectures and frameworks for transforming complex data requirements. If you haven’t checked it out yet, I highly recommend reading the previous posts [here] and [here]. One concept that particularly caught my attention was DataOps, which piqued my interest, especially as I’m also focused on expanding my knowledge of DevOps.
Similar to how DevOps improve the development process and quality of software products, DataOps aims to improve the development process and quality of data products
In this post, we’ll explore the core concepts and technical aspects of DataOps, delving into how it integrates with modern data practices and enhances workflow efficiency.
DataOps Defined

DataOps is a set of practices and cultural habits centered around building robust data systems and delivering high quality data products.
Adopt a cycle of communicating and collaborating with the business
Continuously learning from successes and mistakes
Taking an approach of rapid iteration to work toward improvements to systems and processes

DataOps, like DevOps, leverages lean manufacturing and supply chain principles to combine people, processes, and technology for faster time-to-value.
According to Data Kitchen, DataOps is a set of technical practices, workflows, cultural norms, and architectural patterns that enable:
Rapid cycles of innovation and experimentation, delivering new insights quickly.
High data quality with minimal errors.
Collaboration across diverse teams, technologies, and environments.
Clear measurement and transparency of results.
DevOps vs. DataOps

DevOps is a set of practices and cultural principles that enable software engineers to deliver and maintain high-quality software products efficiently and consistently.

Data products differ from software products in that they focus on business logic and metrics, helping users make decisions or build models for automated actions. While software products provide specific functionality, data products require an understanding of both technical aspects and the business logic, quality, and metrics essential for their success.
DataOps Technical Elements

Automation ensures reliability and consistency in DataOps, enabling data engineers to quickly deploy new features and improve existing workflows.
DevOps: CI/CD automates building, testing, and deploying code, speeding up review and deployment cycles while reducing errors. This boosts efficiency and helps teams build high-quality software products.
DataOps: DataOps automation follows a framework similar to DevOps, encompassing change management (for environment, code, and data version control), continuous integration/continuous deployment (CI/CD), and configuration as code.
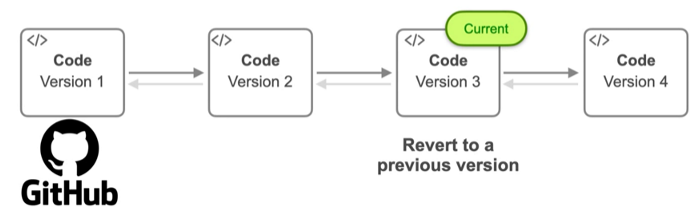
Version Control: Just like tracking code changes, DataOps allows you to track changes in data through your pipelines. If issues arise, you can easily revert to a previous version of the data, ensuring smooth recovery and continuity.


Infrastructure as Code (IaC): You can manage the design of your infrastructure as code, whether building software applications or data pipelines. By defining infrastructure programmatically, you can deploy, modify, and update it as needed. This also allows for version control, making it easy to roll back to a previous version, just like with code or data.


"Everything breaks all the time" - Werner Vogels, CTO Amazon Web Services (AWS)
In addition to monitoring metrics like CPU usage and system response times, as a data engineer, you also need visibility into the health and quality of your data.

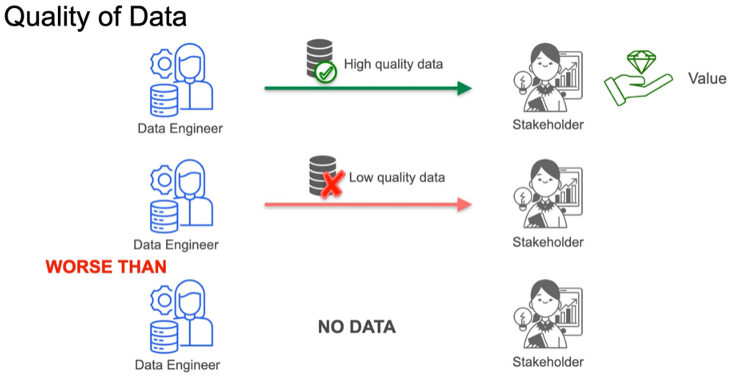
High-quality data accurately reflects stakeholders' expectations, adhering to a well-defined schema and clear data definitions.
Providing high-quality data delivers value to stakeholders, while low-quality data can be more damaging than no data at all. Poor data leads to costly business decisions and undermines the trust in the data team.



Incident response is about using the automation and observability capabilities mentioned previously to rapidly identify root causes of an incident and resolve it as reliably and quickly as possible.
Incident response is not just about the technology and tools used to identify and resolve issues; it’s also about fostering open, blameless communication and coordinating efforts across the data team and the broader organization.
As a data engineer, proactively identify issues before stakeholders report them. Incident response is about both preventing problems and reacting to them.
Depending on a company’s data maturity, a data engineer can integrate DataOps into the engineering lifecycle. For companies with no existing infrastructure, DataOps can be built from the ground up. For those with existing systems, DataOps can be gradually added, starting with observability and monitoring, followed by automation and incident response. In mature companies, a data engineer may collaborate with a DataOps team to enhance the lifecycle. In all cases, a data engineer must understand both the philosophy and technical aspects of DataOps.
About

Benjamin ("Benj") Tabares Jr. is an experienced data practitioner with a strong track record of successfully delivering short- and long-term projects in data engineering, business intelligence, and machine learning. Passionate about solving complex customer challenges, Benj leverages data and technology to create impactful solutions. He collaborates closely with clients and stakeholders to deliver scalable data solutions that unlock business value and drive meaningful insights from data.


Comments